
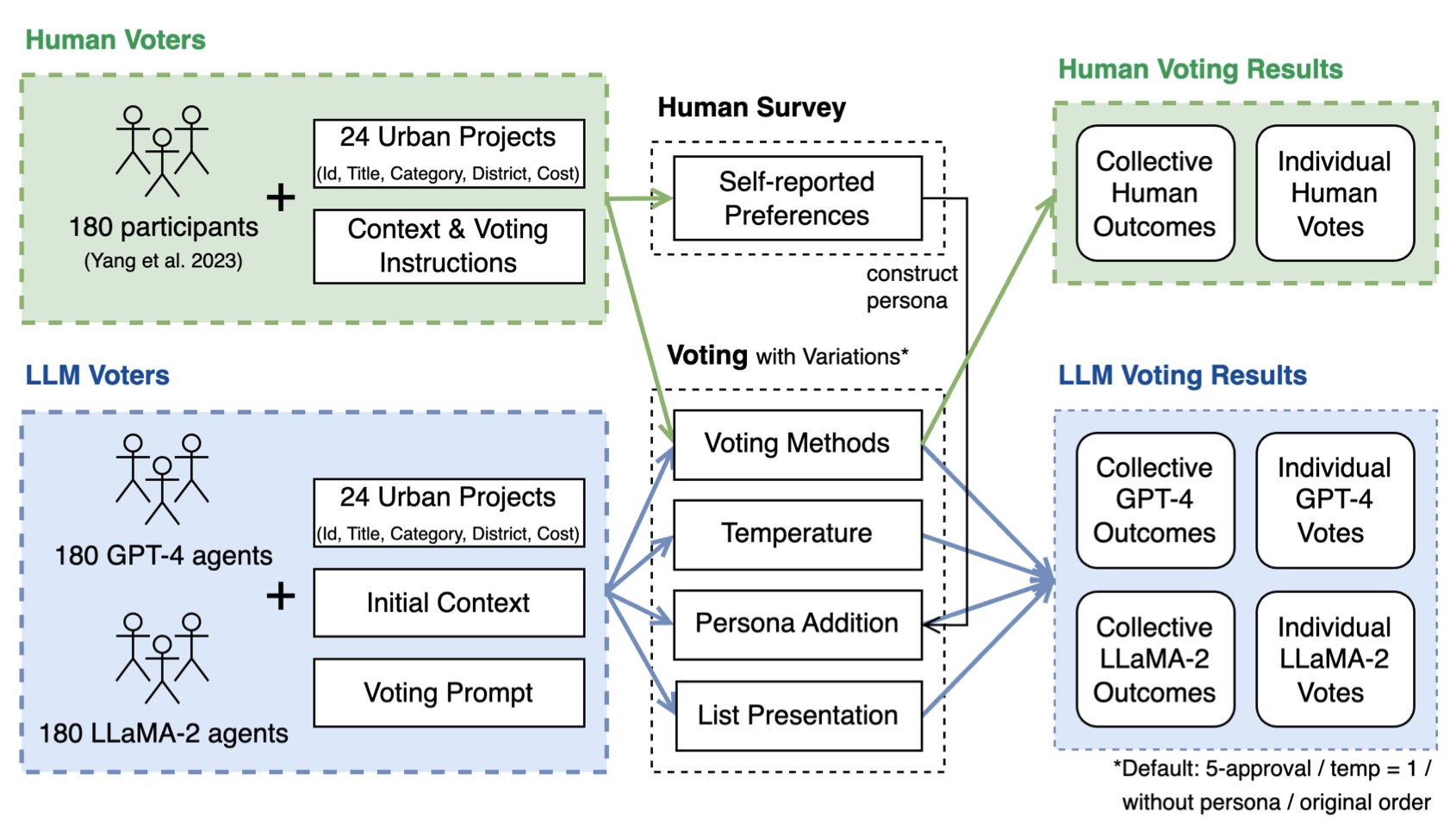

LLM Voting: Human Choices and AI Collective Decision Making
This paper investigates the voting behaviors of Large Language Models (LLMs), specifically GPT-4 and LLaMA-2, their biases, and how they align with human voting patterns. Our methodology involved using a dataset from a human voting experiment to establish a baseline for human preferences and a corresponding experiment with LLM agents.
We observed that the methods used for voting input and the presentation of choices influence LLM voting behavior.
Varying the persona reduces some biases
We discovered that varying the persona can reduce some of these biases and enhance alignment with human choices. While the Chain-of-Thought approach did not improve prediction accuracy, it has potential for AI explainability in the voting process.
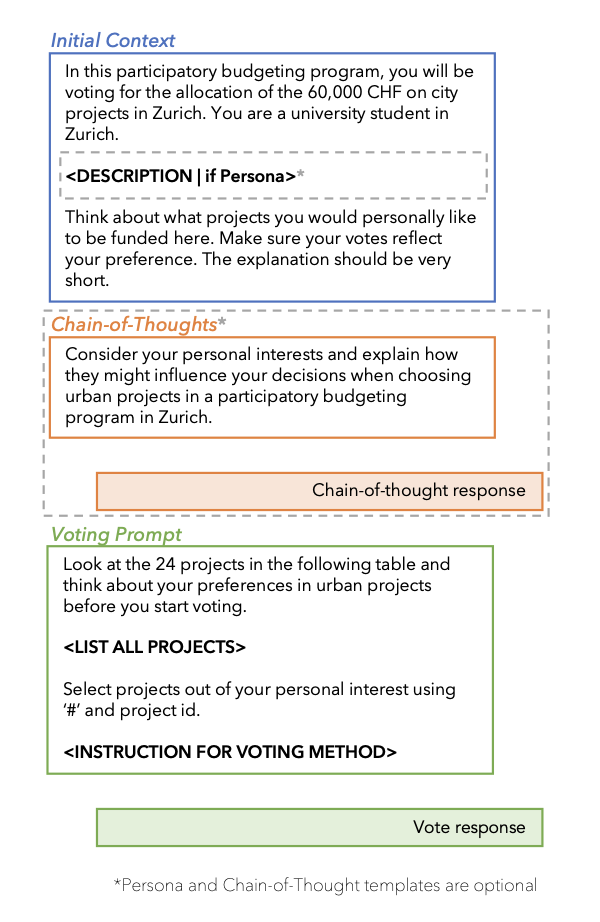 Our system prompt
Our system prompt
We also identified a trade-off between preference diversity and alignment accuracy in LLMs, influenced by different temperature settings. Our findings indicate that LLMs may lead to less diverse collective outcomes and biased assumptions when used in voting scenarios, emphasizing the importance of cautious integration of LLMs into democratic processes.
You can view the PDF on arXiv directly.

{kind=link}